
LeetCode에서 알고리즘 문제를 푸는 사람들이라면 무조건 한 번 쯤은 접해봤을 TreeNode.
Queue를 사용하면 각 노드들의 방향을 알면서 BFS 탐색이 가능하기 때문에
오늘의 문제에서는 Python, C++, Java 각기 다른 언어를 사용해 Queue를 사용한 알고리즘 문제를 풀었다.
Java를 사용한 큐 구현엔 익숙하지만, 아직 Python으로 구현하는 자료 구조들엔 익숙하지 않아
블로그에 포스팅하며 제대로 사용하는 방법을 복기하고자 한다.
Queue란 무엇일까
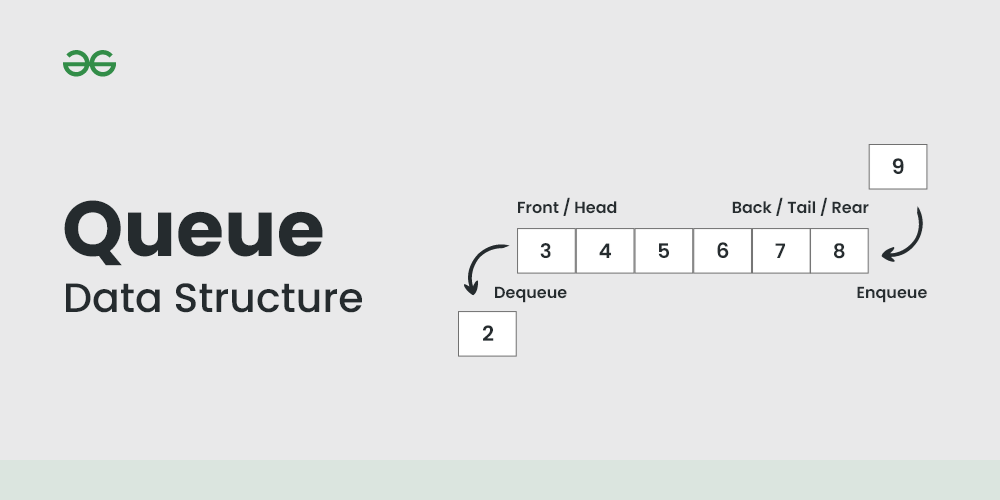
큐는 데이터를 순서대로 처리하기 위해 사용하는 FIFO 구조의 선형 자료 구조이다.
큐의 가장 큰 특징은 FIFO 구조이다.
FIFO(피포; First-In First-Out)란 가장 먼저 온 데이터가 가장 먼저 나가고, 가장 늦게 온 데이터는 가장 뒤에 배치되는 것이다.
몇 문서에서는 큐의 특징을 LILO(Last-In Last-Out)라고 부르기도 하는데,
보통은 Stack의 특성인 LIFO(Last-In First-Out)와 구분하기 위하여 FIFO라고 가장 많이 불린다.
예를 들어 놀이공원의 줄을 기다린다고 가정해보자.
당연히 가장 일찍 줄을 선 사람이 먼저 놀이기구를 탈 것이고, 가장 늦게 온 사람은 저 끝 마지막에서 줄을 서야할 것이다.
큐도 마찬가지로 데이터를 줄 세운다라고 생각하면 될 것 같다.
Queue의 연산
큐가 하는 일은 앞의 데이터를 내보내고, 뒤의 데이터를 삽입하는 일이다.
이 말은 즉슨, 큐의 두 가지 주요 연산은 데이터 삽입/삭제라는 것이다.
- Enqueue: 큐의 끝에 데이터를 추가하는 연산이다.
- Dequeue: 큐의 앞에 데이터를 제거하는 연산.
큐에서 데이터를 가리키는 용어도 맨 앞과 맨 끝만 보면 된다.
- Front / Head: 큐의 앞쪽 끝을 가리키며, 가장 오래된 데이터가 위치한 곳이다.
- Back / Tail / Rear: 큐의 뒤쪽 끝을 가리키며, 가장 최근에 추가된 데이터가 위치한 곳이다.
Queue 구현
이제 큐의 개념을 알았다면 파이썬을 이용한 구현으로 넘어가보자.
역시 무궁무진한 파이썬은 큐를 구현하는 방법도 여러가지가 존재한다.
각 방법은 특정한 용도와 성능에 따라 다른 특성을 가지고 있으므로 필요에 맞추어 사용하면 좋다.
list를 이용한 큐 구현
배열에 사용하는 list의 append()를 사용해 가장 뒤에 데이터를 삽입하고,
데이터를 삭제하며 반환하는 기능의 pop()에 0번 인덱스를 넣어 가장 앞의 데이터를 삭제해준다.
배열에 사용하는 list로 구현하기 때문에 구현이 매우 간단하고, 추가 모듈 import도 필요하지 않다.
그러나, 가변 배열인만큼 리스트의 첫 번째 요소를 제거하고 이후 요소들을 한 칸씩 앞으로 미는 작업 때문에 시간 복잡도가 O(n)이 된다.
가벼운 데이터 조작이나 파이썬 입문자가 큐를 사용하고자 한다면 해당 방법이 편리하지만, 데이터가 커질수록 효율성이 많이 떨어진다.
queue = [] #큐 초기화
queue.append(1) #데이터 삽입
queue.append(2)
queue.pop(0) #데이터 삭제
#큐가 비었는지 여부
if queue:
print("Queue Is Not Empty.")
if not queue:
print("Queue Is Empty.")
collections.deque를 이용한 큐 구현
collections 모듈의 deque를 사용하여 append()를 사용해 데이터를 삽입하고,
popleft()를 사용하여 가장 왼쪽(앞)의 데이터를 삭제해준다. (여기서 popleft는 camel case가 아닌 lower case)
가장 효율적인 큐 구현 방법이다.
삽입과 삭제가 모두 O(1)의 시간복잡도로 수행되므로 리스트를 이용한 큐보다 더욱 효율적이고
스레드 안전성을 제공하기 때문에 멀티스레드 환경에서도 안전하게 사용할 수 있다.
from collections import deque
queue = deque() #큐 초기화
queue.append(1) #데이터 삽입
queue.append(2)
queue.popleft() #데이터 삭제
#큐가 비었는지 여부
if queue:
print("Queue Is Not Empty.")
if not queue:
print("Queue Is Empty.")
queue.Queue를 이용한 큐 구현
queue 모듈의 Queue를 사용하여 put()을 통해 데이터를 삽입하고, get()를 통해 가장 앞의 데이터를 삭제한다.
이 방식은 내부적으로 락을 사용함으로써 스레드의 안정성을 보장한다.
그로 인해 멀티스레드 환경에서 안전하게 사용이 가능하고
그 외에도 최대 크기 설정, 큐가 비었을 때 대기 등 멀티스레드 큐에 필요한 다양한 기능을 제공해준다.
그러나 단일 스레드 환경에서의 단순한 큐 작업에는 락을 사용하기 때문에 성능이 떨어질 수 있고,
다양한 기능이 복잡성을 야기해 다소 과할 수가 있다.
from queue import Queue
queue = Queue() #큐 초기화
queue.put(1) #데이터 삽입
queue.put(2)
queue.get() #데이터 삭제
#큐가 비었는지 여부
if not queue.empty():
print("Queue Is Not Empty.")
if queue.empty():
print("Queue Is Empty.")
위 내용들을 기반으로 각 방법에 대한 장단을 추려보면 다음과 같다.
| 장점 | 단점 | |
| list를 이용한 큐 | 구현 방법이 익숙하고 간단 추가 모듈 필요 X |
연산 시간복잡도가 O(n)으로 비효율적 동적 크기 조정으로 비효율적 메모리 사용 |
| collections.deque를 이용한 큐 | 연산 시간복잡도가 O(1)로 매우 빠름 양방향 큐로 양 끝 연산 가능 |
리스트보다 복잡하여 간단한 작업엔 부적합 |
| queue.Queue를 이용한 큐 | 내부 락으로 스레드 안정성 보장 다양한 큐 관련 기능 제공 |
단일 스레드 상에서 성능 저하 단순한 큐 구현 작업에서 복잡성 증가 |
'프로그래밍 언어 > Python' 카테고리의 다른 글
| 파이썬의 기본 정렬 및 커스텀 정렬 (0) | 2024.08.30 |
|---|---|
| 파이썬에서 우선순위 큐(Priority Queue)를 구현하는 방법 (0) | 2024.08.27 |
| List와 Tuple (0) | 2024.07.17 |